
痛苦金字塔中的工程化(一):威胁情报与方法论
本系列旨在梳理与记录一些威胁情报在落地时的所思所想,并记录一些自己对自己曾经提出的问题的回答。偏向于自问自答的一系列方法论,想到哪里写到哪,不涉及任何代码(应该?)。
威胁情报 & IOC
开篇之前,我们首先需要建立一个共识,威胁情报是什么,引用 Gartner 的一段定义。
威胁情报是某种基于证据的知识,包括上下文、机制、标示、含义和能够执行的建议,这些知识与资产所面临已有的或酝酿中的威胁或危害相关,可用于资产相关主体对威胁或危害的响应或处理决策提供信息支持。
从上面的定义可以发现,威胁情报指的是对于海量数据的筛选与运用,同时集成了对于数据的判断、处理建议。这与我们通常提到的失陷指标(IOC)并不完全相同。
拿 IP 作为例子,127.0.0.1 是一个 IP 地址,它本身可以作为一个失陷指标存在,而威胁情报则包含更多的内容,比如 127.0.0.1 是一个回环地址,通常 localhost 会指向该 IP……等等一系列内容。
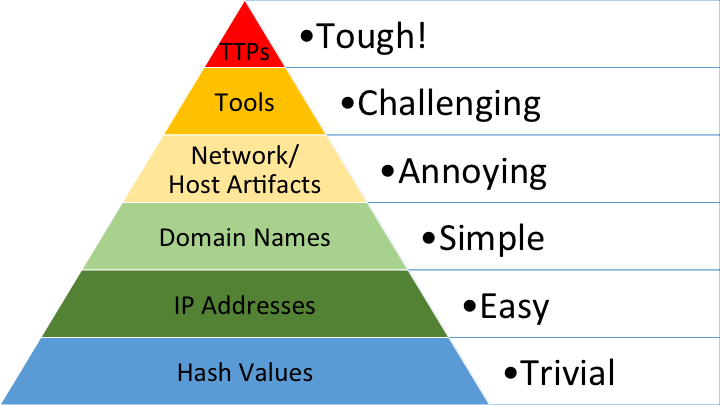
威胁情报 & 痛苦金字塔
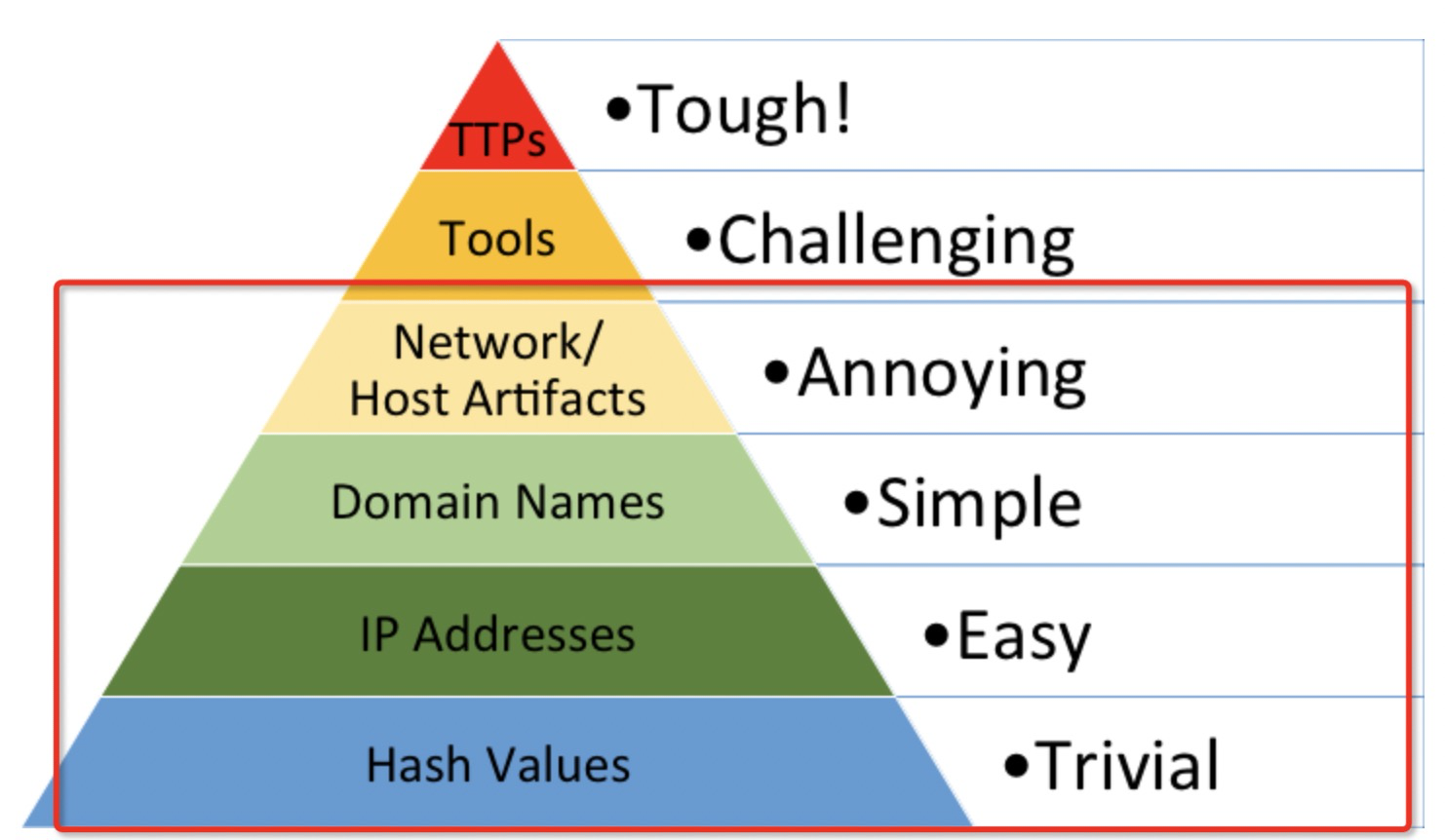
失陷指标在痛苦金字塔中可以归纳在金字塔的下面四层,分别为:Hash、IP、Domain、Network/Host Artifacts。相比于上面的两层内容,他们更具体,更实实在在地存在于网络中,甚至于你的电脑中。而 Tools 与 TTPs 则是研究人员对于已存在实体的归纳形成的总结性概念。(还可以进行其他的分割,以后再填坑)
大体来说,金字塔中的每一层数据由下而上越来越容易获取,每一层的内容都是由下面多层数据进行归纳整理获得的新内容。以最上层为例,TTPs就是由下面五层的内容经过整理、归纳、分析后得出的结论。
(为什么是大体来说呢,因为不是所有的数据都来源于最下层的 Hash。随着越来越多的网络安全设备普及,安全人员可以通过设备告警、流量检测等手段直接提取出 IP、域名等失陷指标。此时的IP与下层Hash是不存在任何推导性的关联的。)
威胁情报则是整个痛苦金字塔本身,既带有基础的失陷指标,同时对于指标进行了研判分析,使得这些失陷指标在现实中具有更多的可操作性。
而通过方法论,我们可以将失陷指标快速而高效地转换为威胁情报。
自问自答
- 我们为什么需要方法论?
- 当数据过于繁杂时,想要快速而准确地找到一个数据并非一件易事。
- 当数据过于独立时,我们想要对数据进行理解、处理、分享都会付出非常庞大的时间成本与人力劳动。
- 当我在说工程化时,我指的是什么?
- 数据的工程化脱离不了一件事情,那就是数据结构。工程化的最基本条件便是需要将不同格式、不同状态的数据合并形成一套完整的体系。将这些看似无关的数据合并、处理,塞入这套体系,从而使杂乱无章的数据变得井井有条。
- 常见的例子:Att&ck、stix、snort等。
- 在有一个完整而稳定的数据结构后,我们才能继续向着自动化迈进。这时的工程化则是对已成型的数据结构的处理。这个阶段,视数据量的大小,通常会涉及规则的整合,数据的过滤,甚至大数据处理等等的内容。需要情报、数据方面的敏锐度和处理的层次度。
- 整合可以参考virusTotal中的关联图,微步的在线情报社区,可以参考他们是怎么将数据进行多维度关联的。
- 当我们成功形成一套体系化的数据处理后, 就需要进行数据化的展示了, 这一点我并没有什么经验, 更倾向于交予专业的数据可视化工程师.
- 一个比较好看的例子: 开源的opencti平台
- 为什么选择痛苦金字塔?
- 痛苦金字塔是威胁情报中非常典型的模型,每一个想要了解威胁情报的人都会对其有所了解
- 痛苦金字塔非常的简洁,直观,更有利于内容的传播。
- 相较于钻石模型,它更具有抽象与具象化的对比;相较于杀伤链,它更偏向于静态的数据研究,因而更适于防守方做情报归纳;