
痛苦金字塔中的工程化(二):当样本分析遇到威胁情报
样本分析报告是威胁情报的一个主要产出点。我们可以这样理解:每一篇分析文章的产生,都是一次情报的共享。
本篇我们会以一个样本分析的视角,来看看什么是痛苦金字塔,以及如何从一篇分析报告中提取出我们想要的内容。
样本 & 报告
样本:在样本分析中,样本指任何交到手里的二进制文件,可以是开源的、不开源的黑客工具、脚本、自主开发的木马、正常的程序、甚至无法执行的BIN等等。
本次例子使用的报告来自于盘古实验室对于方程式组织的Bvp47后门的分析报告,该报告附带了对于样本的完整分析、关联,还有对于整个事件的介绍、总结与受害范围,完整性与关联性都非常地高。不过碍于样本本身与影子经纪人事件均为多年前的事件,有旧瓶装新酒的嫌疑,也有些人会以这一点进行攻击,不过这些都不妨碍它成为一份详尽的报告。
报告结构
我们可以将整个大体地报告内容分为两个大类:事件层面 & 技术层面

- 事件层面
事件层面包含了更容易让大多数人理解的内容:- 攻击者是谁?
- 为什么要进行攻击?
- 怎么找到的攻击者?
等等一系列问题。
事件层面的内容通常是我们比较关注的内容,但这些信息通常出现在事件调查的尾声。也就是说,只有在了解了手中的样本之后,才会对这个事件做出一个系统性的总结与关联。而这些内容,也是我们上篇介绍的痛苦金字塔的顶部内容。
既然是痛苦金字塔中最痛苦的地方,必然不会是在每个报告中都存在的。多数时候,可以处理到事件关联的报告都会以一个比较正式的PDF附件的形式作为某个事件调查的详细内容出现。
- 技术层面
技术层面则包含更多分析人员关注的内容:- 这是个什么样本?
- 样本都做了些什么?
- 有什么值得关注的技术点吗?
等等类似的问题。
技术层面的内容更偏向一篇传统的样本分析报告,研究人员对于整个样本进行样本流程上的分析和样本特征的分析,并不会过多关注于攻击者本身的意图和影响。这样的报告更多的情况下会以一篇博客、一篇公众号文章的形式分享出来。
现在,整个报告的结构拆分出来了,让我们看看其中的细节吧。
报告中的威胁情报
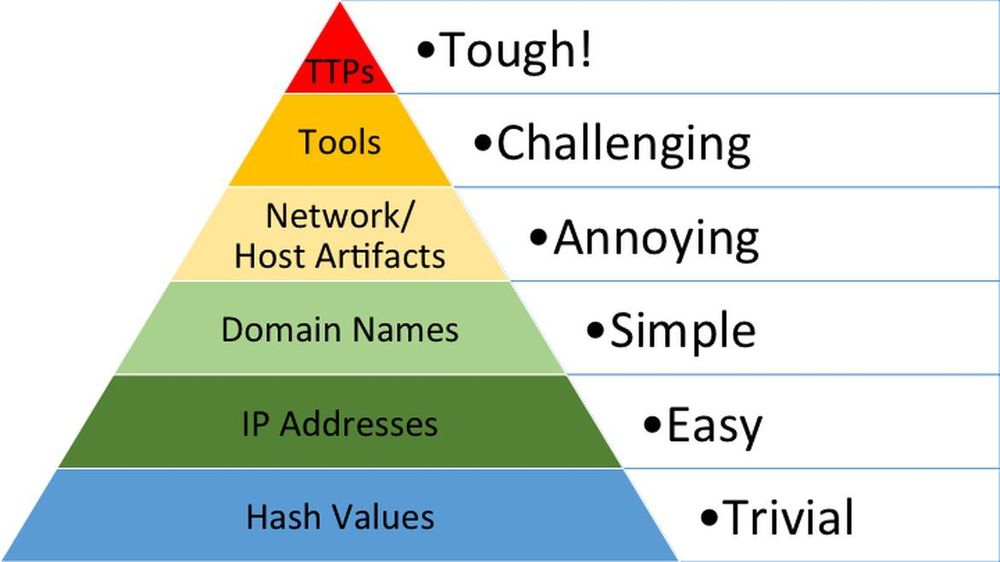
以 前所未见的后门 一节为例,该章节主要对整个后门的执行流程进行了描述。作为威胁情报的处理人员,我们要如何看待这份报告呢?读完之后,对于整个报告的第一反应,大概是下面这张图:

但这样的数据对于情报处理来说过于抽象,无法集成为有效而具体的情报。于是我们按照文章中描述的数据通信流程进行还原,可以得到下面这样的例子:

或者这样:
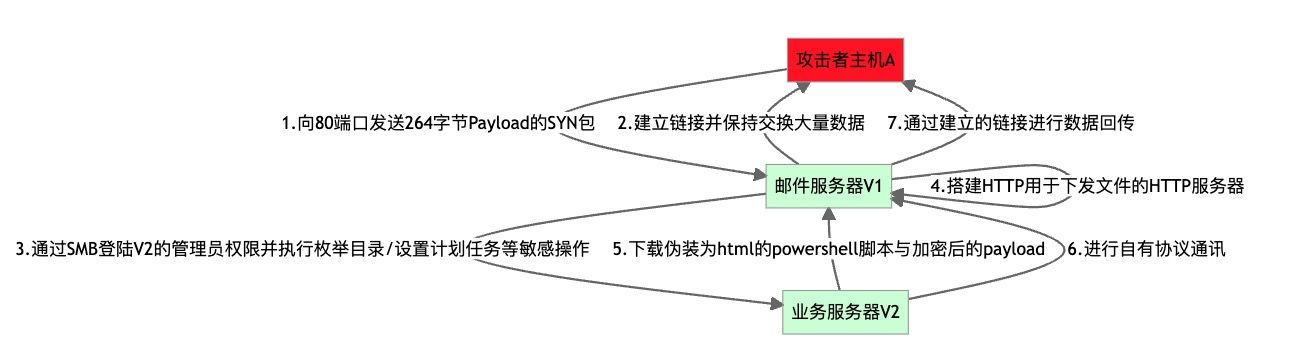
依然不够。
我们希望收集到的威胁情报应该具备这样的特质:具体且独特。上面的流程图依然不具备。
当然,这已经是一张非常完整的样本流程图了,但我们需要了解到的信息不仅仅如此。比方说,启动的后门程序的哈希值是什么、SYN包的内容又是什么、交换的大量数据都是什么、通过SMB具体执行了什么样的操作,这些操作执行后会在机器上留下什么样的痕迹……这些都是我们需要知道的内容。
但多数时候,因为篇幅、编写难度、等等一系列原因,想要只看报告就可以获取所有的细节是不太可能的。这时候可以通过报告中留下的MD5、IP等线索,抓取到样本并进行分析。甚至有的时候还可以通过这样的分析进行情报的二次挖掘。
当然,我们并没有时间或者对应的技术能力对所有看到的报告进行分析。大多数时间,威胁情报的处理人员会将报告中的常见的IOC进行提取处理,形成可以被批量处理的IOC。
情报处理
了解了整个样本的执行流程,现在我们需要做的就是把细节提取出来了。这些被提取出来的数据被统称为IOC(Indicator of compromise),也是我们在工程化中需要存储的数据。
这时,面对这些细节,我们最少会有两个问题:
- 它有效吗?
- 我能提取它吗?
那么就拿一些报告里的例子来回答这两个问题吧。
- 样本哈希
有效。每个样本的哈希值唯一,且哈希计算方法决定了该值大概率不会和其他样本重复。
可以提取。样本哈希值通常根据计算方法分为三类,MD5、SHA1、SHA256。每个类型的样本哈希长度不同,但是确定。例:MD5的一定由长度为32的十六进制数字组成。

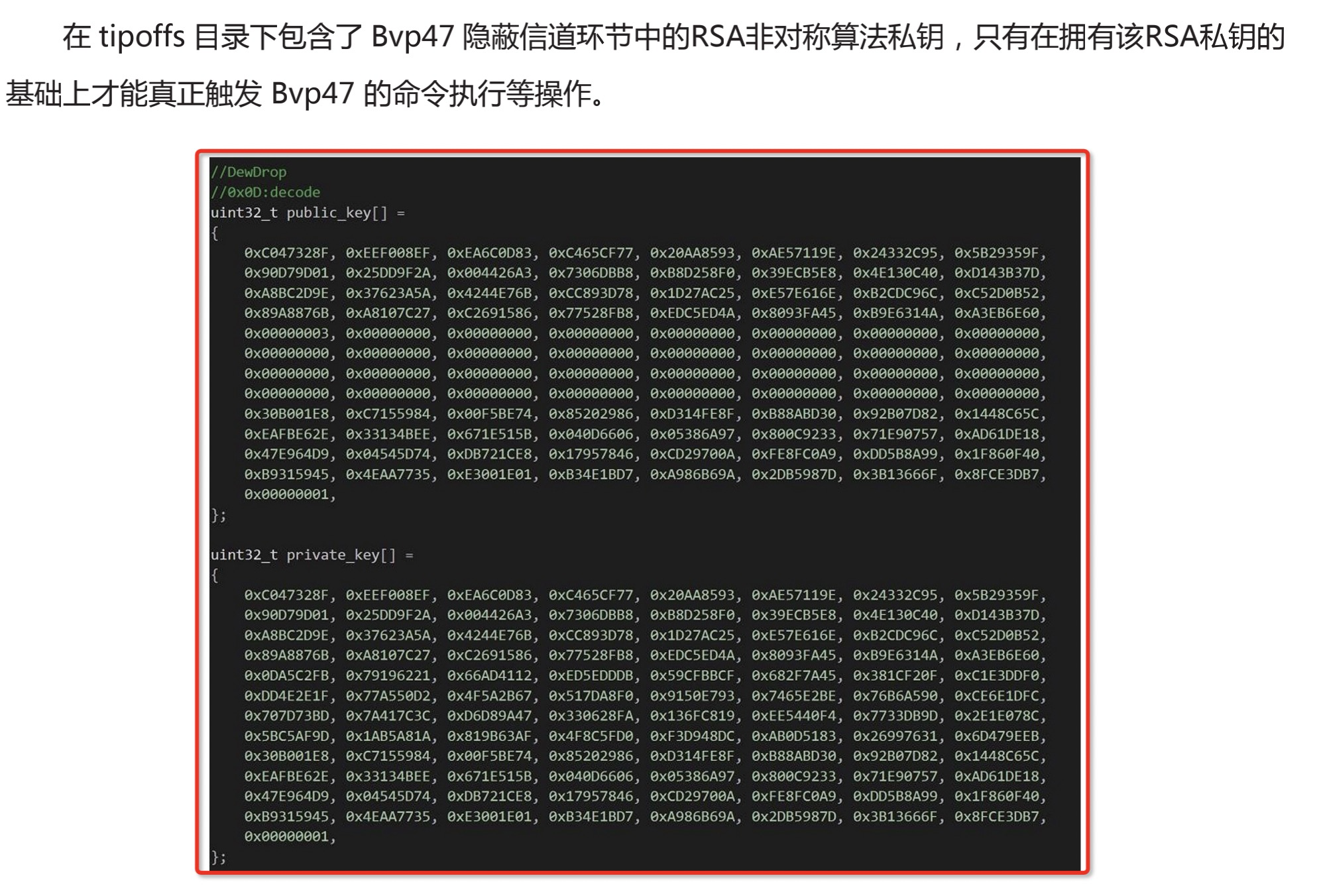
- RSA 私钥
有效。RSA加密算法中出现同样公私钥的概率微乎其微,同样的公私钥都用于恶意样本的可能行就更小了。该私钥也是本篇报告中判断该样本后门与方程式组织存在联系的重要证据之一。
可以提取。下图中框出的数据为RSA公钥与私钥,以十六进制形式展示。只是出现的频率相对更少,通常的IOC提取和共享流程中并不包括RSA Key。
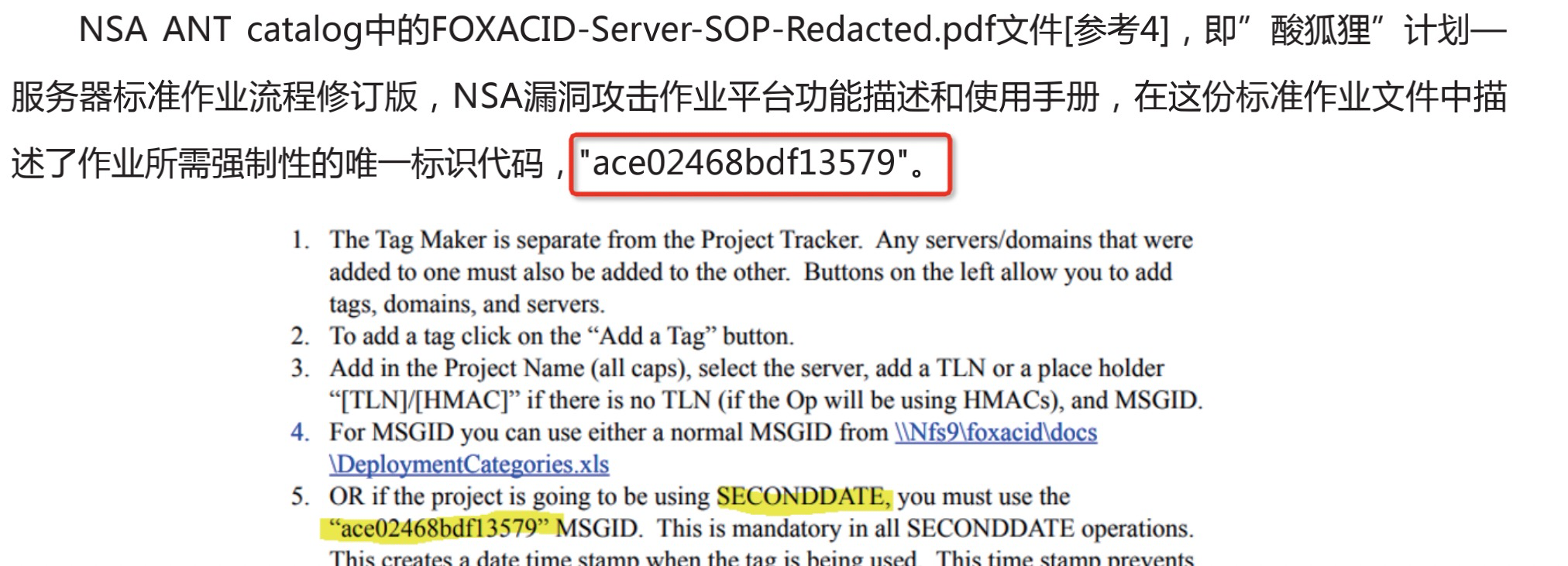
- 标识码
有效。具有非常强的唯一性,和独特性。也是本篇报告中判断样本与该组织的关联之一。
可以提取。但由于该标识码过于独特,通常的IOC提取也不会带上它。
- 受害者列表
可能有效。可以对整个事件的受害方向做总结,但是域名与IP本身存在一个使用的实效性,可能几年、几月、几天、甚至只有几个小时。遇到这种情况需要根据更多内容进行研判。
可以提取。但如果是批量话的IOC提取,建议直接删除。像IP、域名这种数据,多数批量提取出的内容会被用于威胁情报、防护规则中。如果将内容单纯提取出来,容易误导情报的处理者,将受害者误当作攻击者进行处理。
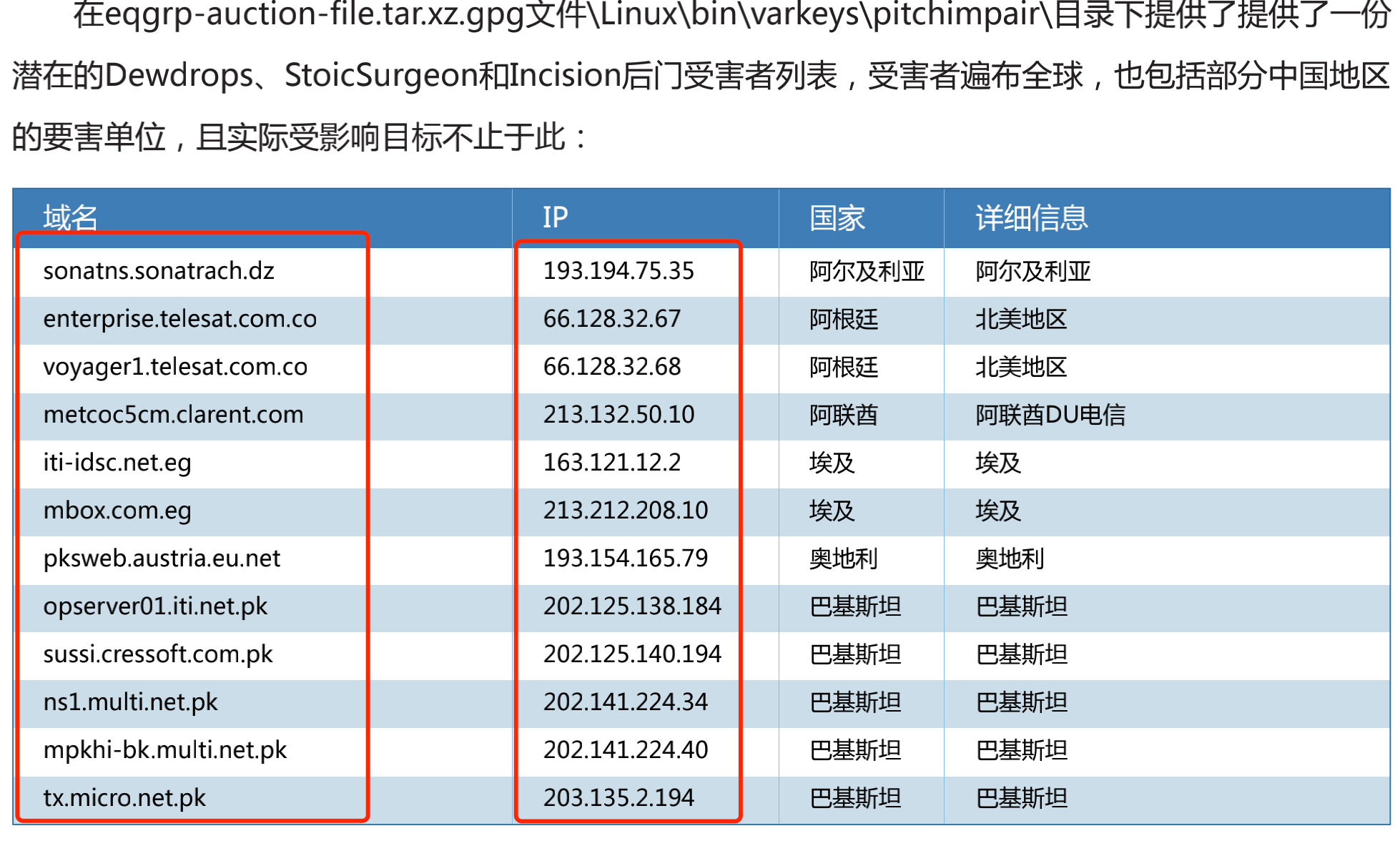
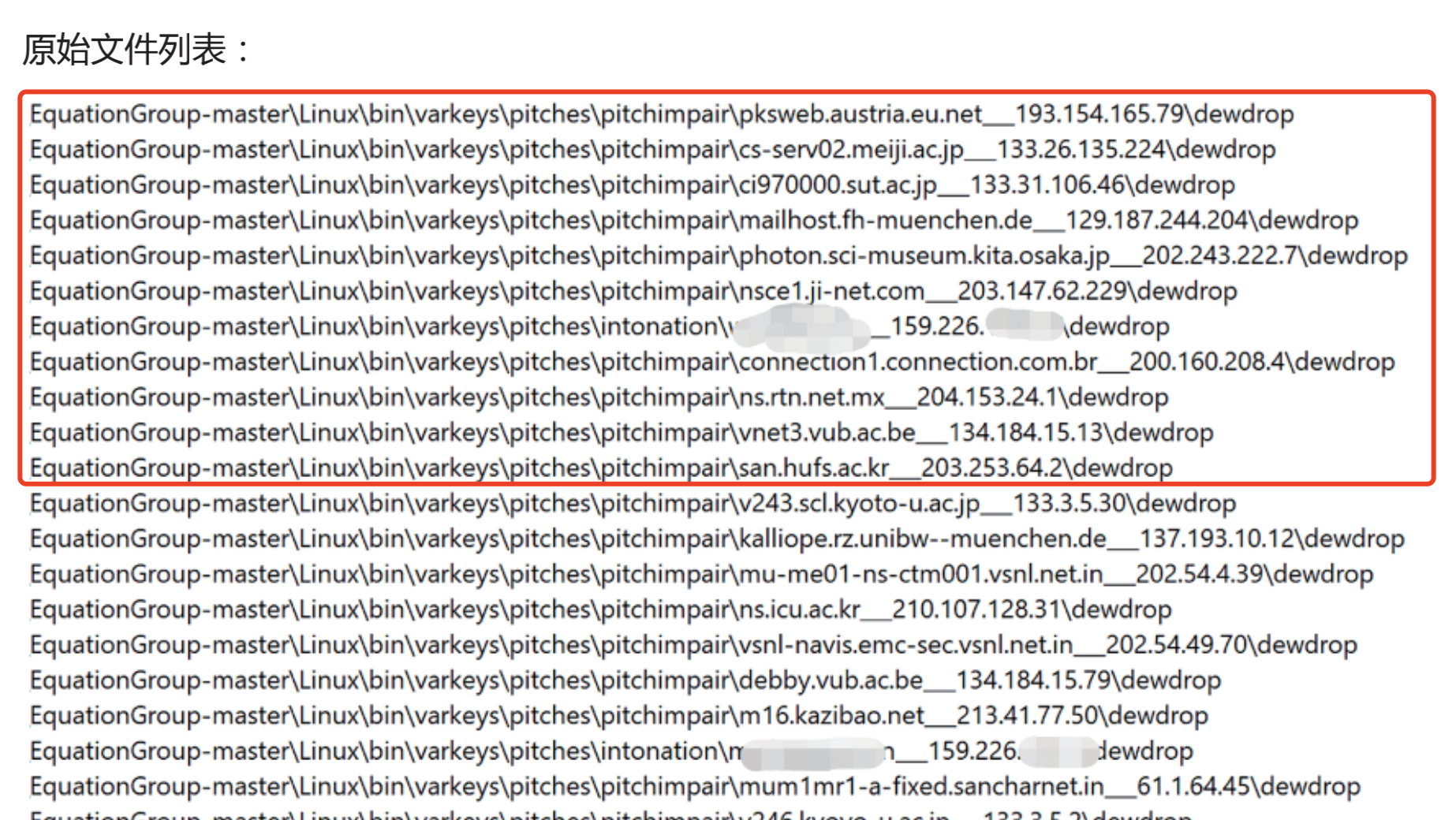
- 原始文件列表
可能有效。原始文件列表可以总结为一套规律的文件存储路径,但是文件路径替换代价非常小
可以提取。这个文件路径特征比较强,如果文件路径过于常见就不要提取了,会在后续使用的时候出现很多false positive。
- 内核信息(哈希值)
可能有效。如果你想知道样本的可影响范围,它有一点点用。
不建议提取。内核哈希,和样本本身无关。

- 函数处理技巧
有效。包括样本流程、整个文件结构、样本处理手法等等。虽然他们非常抽象,但很多信息都可以从这些抽象的内容中获取。
无法提取。过于抽象,无法进行统一提取。除非存在一套标准,可以将抽象的行为具像化归类。一般会在找到一些特征后,阅读整个报告来匹配这些更抽象一些的内容。
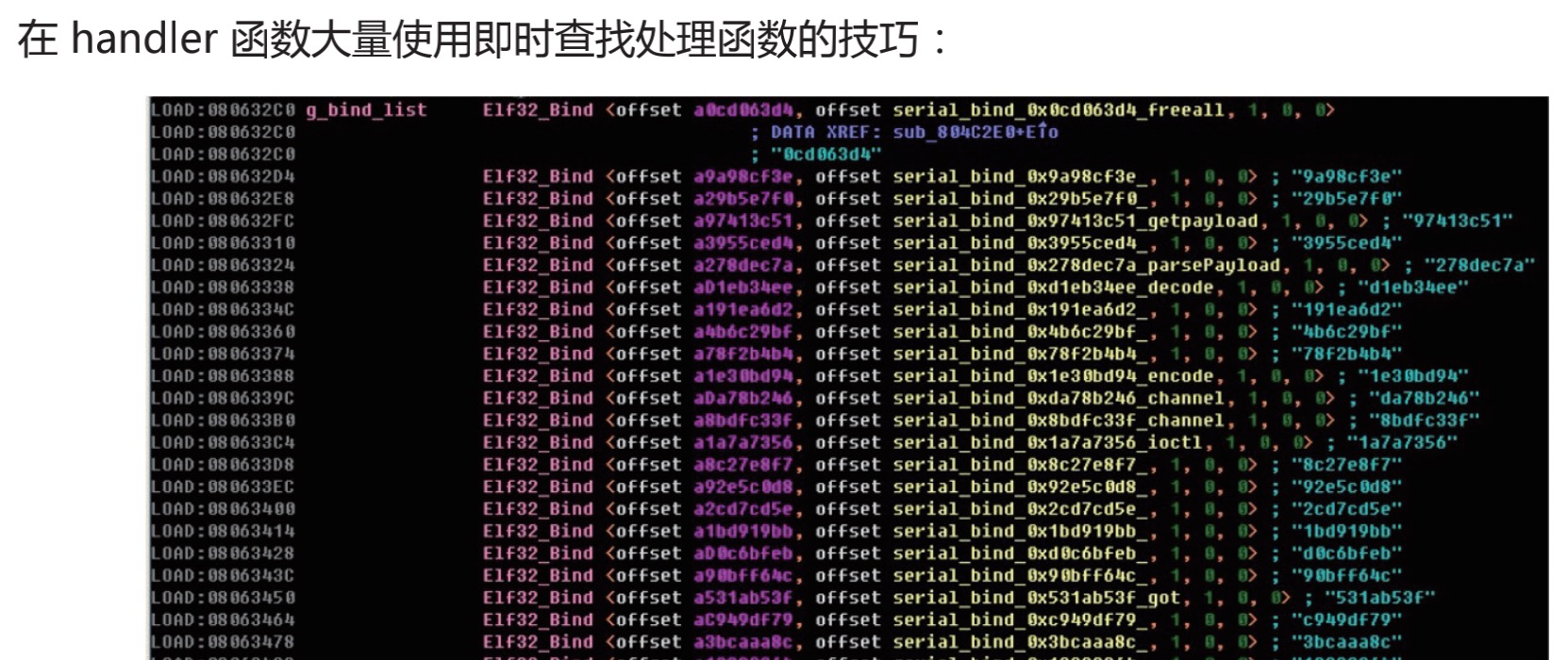
还有像字段结构、环境校验方法等。可以对照着报告和样本来思考一下这两个问题。
痛苦金字塔
了解了报告中的各种内容,现在将它们归类进金字塔看看吧。

可以看到,在筛选完情报之后,这些情报可以被完美地塞入痛苦金字塔模型中。反之亦然,痛苦金字塔也可以作为标准,按照一节一节的台阶进行数据填充,当一个金字塔的每一层都被填充后,就可以算是提取到完整的情报了。
情报提取
通过上面一系列的情报评估,我们可以得到这样一个认知:不是所有的情报都是有效的情报, 而不是所有有效情报都可以被格式化提取的。
可以被批量提取的IOC们都会有一些特征,更方便于情报分析人员进行大批量、格式化的处理。
常见的IOC类型包括:IP、域名、哈希 等。
工程化
随便放几个情报提取的工具和直接的情报来源吧。
-
自动化的ioc提取
-
ioc_parser
Github 的开源项目,通过正则将常见的IOC类型从报告中提取出来。
https://github.com/armbues/ioc_parser -
yeti
开源的威胁情报平台,内部集成了一个非常友好的报告解析系统,但平台代码本身依然存在一些小小的问题,使用时候的流畅性无法保证。
https://github.com/yeti-platform/yeti
-
-
IOC直接来源
-
Alien Vault
开放的威胁情报社区,有很多人将不同的国家不同地区的报告整理成一个个 pulse。可以根据报告搜索,也可以根据IOC进行搜索。
https://otx.alienvault.com/ -
Covert.io
很多安全厂商会在发布自己报告的同时发布一份IOC列表,或者由他人二次加工后形成一个IOC库,我们通常将这种定期维护的IOC库称为Feed。有人会将各种Feed地址整理,做数据的二次集成,比方说下面的链接。
-
报告中的IOC - 优点&弊端
优点:稳定、时效性长、锤得够狠
缺点:更片面、样本分析更注重于受害者视角的分析,例如:我是如何被攻击的。而这对于我们在威胁情报中还原攻击者行动轨迹是比较困难的。
当然,如果将提取出来的IOC用于威胁狩猎则是没有问题的,这也是业内现在广泛的用法之一。